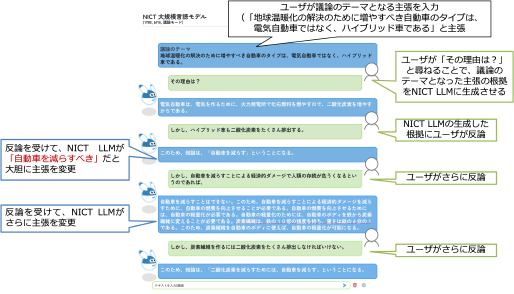
1. 大規模言語モデルNICT LLM
NICT LLMは、WISDOM XやMICSUSなどの開発で培った高精度な言語処理・深層学習技術と、構築済みの350GBもしくは888GBの高品質な独自の日本語Webテキストを用いて開発した、NICT独自の生成系大規模言語モデルです。 これまでに、130億パラメータから1,790億パラメータ(OpenAI社のGPT-3と同等規模)、さらには日本語特化型では世界最大規模の大規模言語モデルとなる3,110億パラメータまで、パラメータ数を変えたさまざまなモデルの事前学習を完了し、特にファインチューニング等を行わなくても、事前学習のみで一定の精度で質問応答、創作、議論等が可能なことを確認し、また、モデルの大規模化と学習用テキストの大規模化に伴う性能向上を確認しています。
このNICT LLMの開発に関して2023年7月にプレスリリース「日本語に特化した大規模言語モデル(生成AI)を試作」を実施、多くの新聞やネットメディアで報道されています。 NHKニュース7でも当研究センターの活動が紹介されました。
現在、偽情報を生成するハルシネーション等の生成系大規模言語モデルの副作用の抑制を目指して、WISDOM Xを活用した情報を確認する機構や、複数のLLM同志が議論を行って最終的な情報を生成するシステムの検討にも着手しています。また、NICT LLMおよび関連技術の社会実装に向け、MICSUSなどの対話システムへの導入を計画するとともに、NICTで収集・開発した言語資源や言語モデル、研究知見などを共同研究等を通して民間等に提供する準備も進めています。2024年7月1日にKDDIとの共同研究を開始しました。


- NICTとKDDIが大規模言語モデルに関する共同研究を開始 (NICTのプレスリリース:2024年7月1日)
- NICTにおける大規模言語モデル(LLM)への取り組み (NICTオープンハウス2024)
- Building prototype Japanese language specific Large Language Models (LLM, Generative AI) NICT REPORT 2024
- 国産生成AIの開発進む「豊富な日本語の学習データが強み」 NHKニュース7:2023年12月1日
- 生成AIが互いに議論? 国立法人NICTが目指す「フェイクを見破る術」とは ITmediaビジネスオンライン 連載「生成AI 動き始めた企業たち」第8回:2023年9月6日
- 日本語に特化した大規模言語モデル(生成AI)を試作 NICTのプレスリリース:2023年7月4日
2. 高齢者介護支援マルチモーダル音声対話システムMICSUS
MICSUSは、異次元の高齢化が進み介護人材の逼迫が喫緊の課題となる中、現在は人間の介護者(ケアマネジャー)が月一回程度面談で行なっている、 介護モニタリングと言われる高齢者の健康状態や生活習慣のチェックの一部を音声対話を通じて代替し、介護者の作業負担を軽減するための対話システムです。 また、Web情報を用いた雑談も行い、高齢者のコミュニケーション不足の抑制も狙っています。 内閣府戦略的イノベーション創造プログラム(SIP)第2期の支援により、KDDI株式会社、 NECソリューションイノベータ株式会社、株式会社日本総合研究所と共同で開発しました。
音声認識誤りに頑健な独自開発のHBERTを300万件のオリジナル学習データでファインチューニングしたモデルを活用し、遠まわしな言い回しなどを含む様々な発話に対して高精度な意味解釈を実現し、 高齢者との対話から健康状態や生活習慣の情報を適切に抽出します。 2022年度に全国各地の高齢者179名を対象に実証実験(総対話時間95.3時間、26,704ターン)を実施して評価を行いました。 実施後のアンケートで5段階中4.2と高評価をいただくとともに、言語処理の部分ではYES/NO疑問文への回答を93.5%の高精度で正しく意味解釈できています。 雑談的応答に関しても、91.8%が雑談として適切、25.4%に対して高齢者が笑顔を見せるなど、51.9%に対して高齢者が好意的反応を示し、雑談のクオリティは良好と言えます。
また、CEATEC2022、HANAZONO EXPO、けいはんなR&Dフェア2023など、 様々なイベントに出展して多くの家族づれや介護関係者にMICSUSとの対話を体験していただいています。
今後も、多数の民間企業と連携して本技術の社会実装に向けた強化を進めるとともに、さまざまな社会課題の解決、回避に向け、言語、音声の高度かつ高精度な意味的処理の実現を目指して研究開発を行います。 研究開発成果を、要素技術単位でKDDIをはじめとするさまざまな企業、組織にライセンス等を通して提供し、技術の社会実装に取り組んでいきます。 また、大規模言語モデルなどの最新の言語処理技術の応用も図っていきます。


高知県日高村での実証実験の様子(KDDI提供)
MICSUSの詳しい紹介は、以下のサイトや動画をご覧ください。
- 高齢者向け対話AIでケアマネジャー面談業務時間の7割削減に成功 NICTのお知らせ:2023年3月8日
- 介護人材不足解消に向け、対話AI搭載型ロボットによる介護実証を実施 KDDIのニュースリリース:2023年11月13日
- SIP第2期「ビッグデータ・AIを活用したサイバー空間基盤技術」研究成果報告書(2018年度~2022年度) 2023年 3月発行
- 高齢者介護支援用マルチモーダル音声対話システムMICSUS 情報通信研究機構研究報告 2022年12月発行
研究紹介ムービー『NICTステーション ~MICSUS~』(NA上白石萌音)
マルチモーダル音声対話システムMICSUS紹介動画
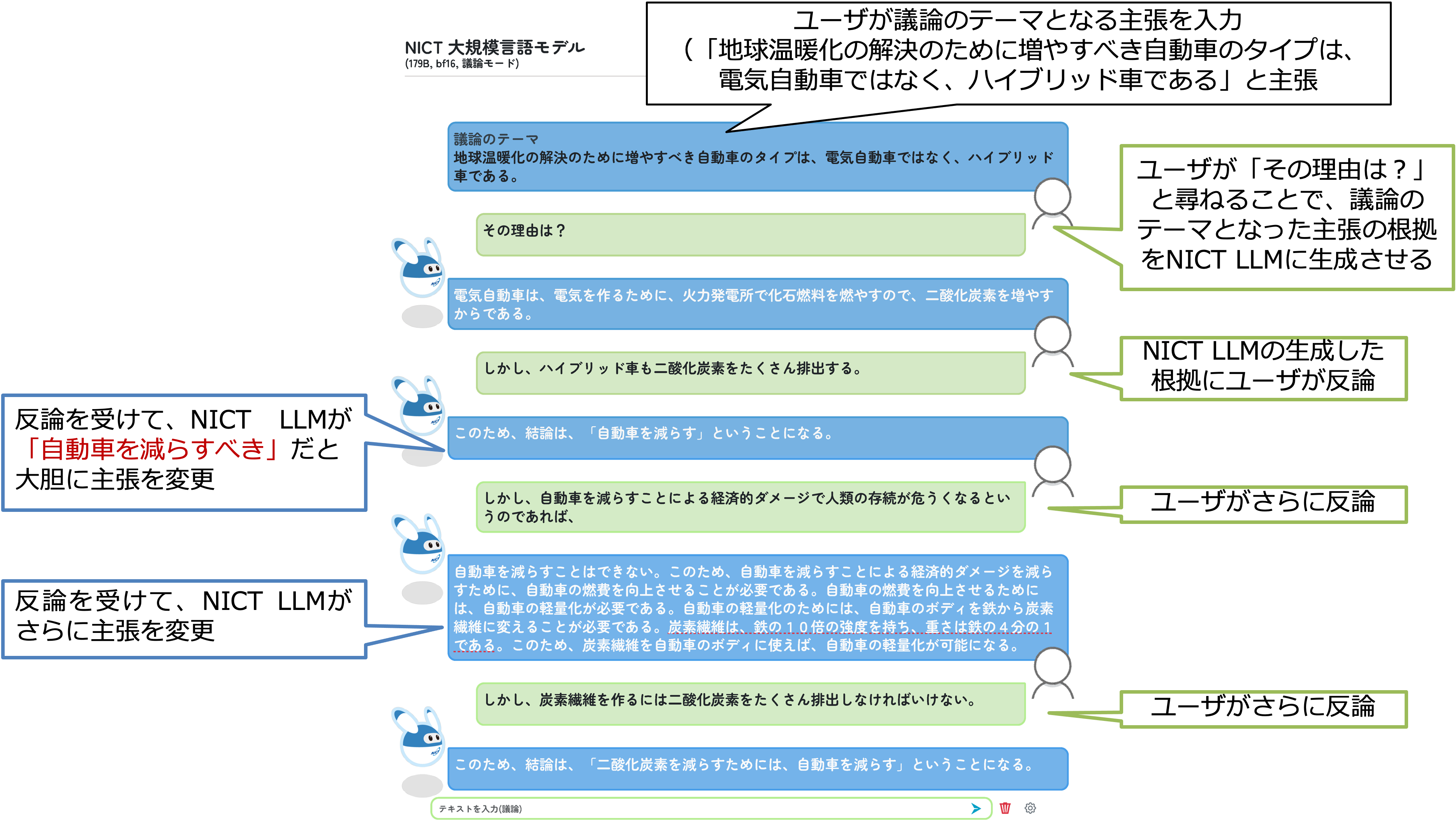
3. 大規模Web情報分析システムWISDOM X 深層学習版
2021年3月31日より、Web60億ページの情報を基に様々な質問に回答することができる大規模Web情報分析システムWISDOM X(ウィズダムエックス)「深層学習版」の試験公開を開始しました。 2015年3月31日より試験公開しておりましたバージョンでは、Web40億ページの情報を基に「なに」「なぜ」「どうなる」といったタイプの様々な質問に回答することが出来ましたが、「深層学習版」では、新たに「どうやって」(How-to)型の質問にも対応しました。 これらの様々な質問応答を通して関連情報の全体像を迅速かつ容易に把握できるようにし、価値ある想定外の発見も容易にします。 WISDOM Xは、近年、重要性を増しているイノベーションやリスク管理といった不確実性に対処する作業において価値ある考えるヒントを提供できると考えています。
2023年6月12日にニアリアルタイム解析を導入し、収集したWebページを即時に解析し、WISDOM Xの分析対象とするようにしました。 これにより一部の最新の情報に対しても質問の回答が行えるようになっています。 (ただし、収集した時点で最新情報かどうかはわかりませんので、最新情報がすべて検索可能になっているわけではありません。)
2023年12月18日に深層学習モデルを更新しました(分析対象はWeb176億ページ以上)。「なぜ?」、「どうやって?」タイプの質問において実験では精度が5%以上向上しています。
深層学習版の詳細につきましては以下のリンクをご覧ください。



4. 災害状況要約システムD-SUMM
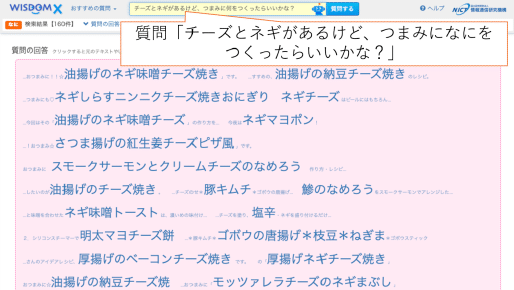
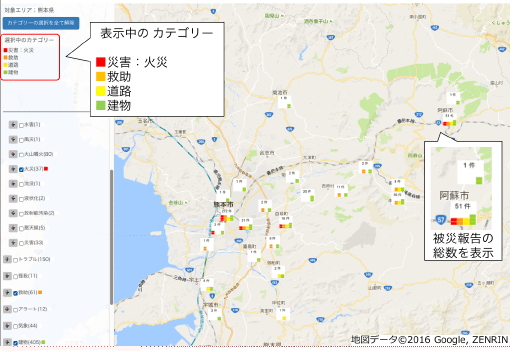
災害状況要約システム D-SUMM は、Twitter上の災害情報を、わかりやすく整理、要約することによって、救援、避難等を支援するシステムです。DISAANAでは、「火災が発生している」「火事が起きている」など意味的に類似する被災報告が別々に出力されていましたが、D-SUMMでは、災害情報の意味的な分類を精査し、これらの報告をひとまとめにすることで、災害状況を、よりコンパクトかつ、わかりやすく提示することができるようになりました。エリア毎または、災害カテゴリー毎に災害情報を要約することができ、それらを地図上に表示することも可能です。2016年10月18日より試験公開しています。
なお試験公開は、2023年12月28日をもって終了させていただきました。ご利用、ありがとうございました。


5. 次世代音声対話システムWEKDA
WEKDA (WEb-based Knowledge Disseminating dialog Agent) は、ユーザが入力した発話に対して、質問を自動生成し、WISDOM Xで回答を探し、応答を生成する音声対話システムです。 このシステムでは、例えば「iPS細胞ってすごいよね」「煮物が食べたい」といったユーザの音声入力に対して、「iPS細胞で何を見る?」「煮物に何が良い?」といった質問を自動生成し、その質問に対してWISDOM Xが提供する回答(「治療薬候補」「和風な朝御飯」等)を基に、「iPS細胞で肥大型心筋症の治療薬候補を見つけた」「焼き魚に玉子に煮物で和風な朝御飯も良し」といった応答を生成します。これらの質問は、システムの応答の背後にある自然な意図や動機といったものに対応します。ユーザは、こうした応答によって、価値ある知識を取得したり、近々の生活を豊かにするヒントを得ることが可能になります。 詳しくは以下の発表文献やプレスリリースをご参照ください。
WEKDA:Web40億ページを知識源とする質問応答システムを用いた博学対話システム 水野淳太, クロエツェージュリアン, 田仲正弘, 飯田龍, 呉鍾勲, 石田諒, 淺尾仁彦, 福原裕一, 藤原一毅, 大西可奈子, 阿部憲幸, 大竹清敬, 鳥澤健太郎, 第84回言語・音声理解と対話処理研究会資料, pp.135-142, 2018年11月.




6. 対災害SNS情報分析システムDISAANA
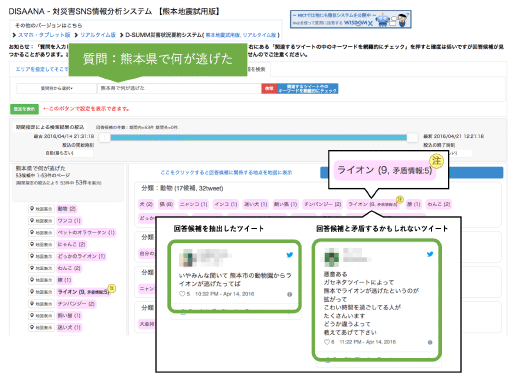
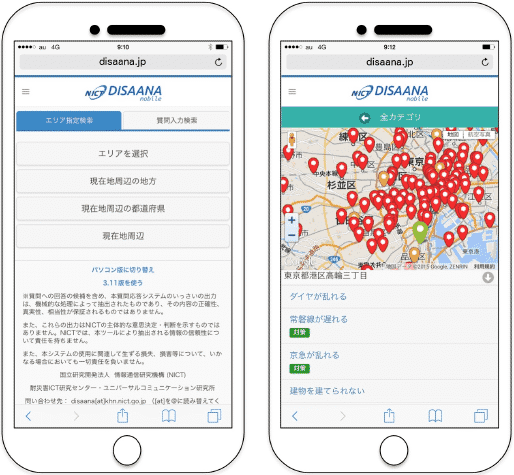
当機構耐災害ICT研究センター応用領域研究室と共同で、「今、まさに発信されている」Twitter上の災害情報をリアルタイムで分析し、質問に回答する対災害SNS情報分析システムDISAANAを開発し、2015年4月8日より試験公開しています。スマートフォンからアクセスしますと、スマートフォン対応版をお使いになれる他、熊本地震時のTwitterデータを分析できる試用版もお試しいただけます。
なお試験公開は、2023年12月28日をもって終了させていただきました。ご利用、ありがとうございました。


7. 大規模Web情報分析システムWISDOM X
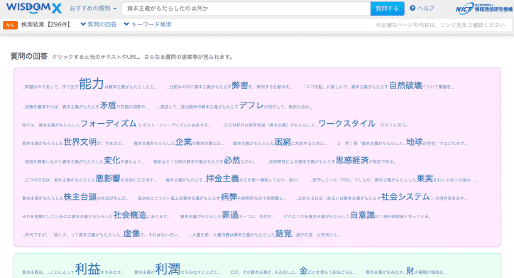
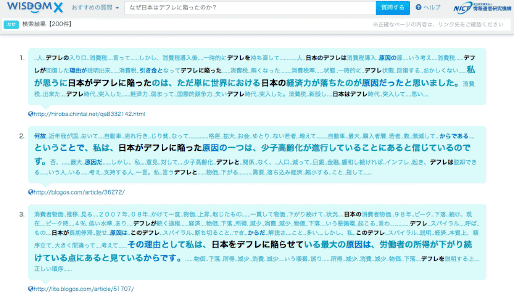
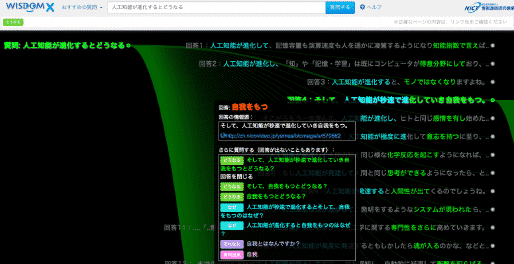
40億件以上のWebページを深く意味まで分析し、「なに?」「なぜ?」「どうなる?」といったタイプの様々な質問に回答する大規模Web情報分析システム WISDOM X を開発し、2015年3月31日より試験公開しています。どのような質問を入力すべきかわからない場合には、キーワードを入力すると回答可能な質問を提案する他、質問の回答からさらなる質問を提案し、情報のさらなる深堀りを行ったり、Web上に書かれていない仮説を生成したりすることも可能です。



8. 情報分析システム WISDOM
Web情報を様々な観点から分析・集約し、提示するシステムです。
旧知識処理グループ情報信頼性プロジェクトで開発されました。
9. 音声質問応答システム一休紹介ビデオ
スマートフォンに音声で入力された多様な質問に意外な回答まで含めて回答します。
旧言語基盤グループで開発されました。
*音声認識器は、音声コミュニケーショングループのものを利用しています
自動発見された推論規則によって推論された仮説の回答も含めて回答します。
