情報通信研究機構
データ駆動知能システム研究センター

データ駆動知能システム研究センターでは、Web等に存在する大量のテキストを深く意味的に分析し、情報の価値ある組み合わせや、価値ある仮説を柔軟な入力を元に提示できる技術を開発しています。ますます複雑化していく現代社会において、一見かけ離れた情報間の予想もしなかった繋がりが非常に重大な帰結をもたらす事例がますます頻繁におきています。我々の目指す技術はそうした情報間の組み合わせをユーザに分かりやすい形で入手可能にするものです。より具体的には、文の同義性やテキストに書かれた因果関係などの事象間の意味的関係を元に、ユーザの多様なニーズに応えられる情報やその組み合わせ、あるいは仮説を、Web等に存在する膨大な情報源をもとに生成する技術です。こうした技術の開発には先進的な言語処理技術、膨大な言語資源が必要となりますが、これまでに開発してきた最先端技術や、関連分野を研究する公的機関としては日本最大級の計算リソースを用いてこれらの研究開発に挑んでいます。
代表的な成果は以下の3点です。1. 大規模言語モデルNICT LLM、2. 高齢者介護支援マルチモーダル音声対話システムMICSUS、3. 大規模Web情報分析システムWISDOM X 深層学習版
NEWS & TOPICS
- New 鳥澤フェローが、第14回 日経「星新一賞」の最終審査員に選出されました ()
- New 電波タイムズによるNICTオープンハウス2026のレポート記事で、LLM生成テキスト検証サービスWISDOM-CEが詳しく紹介されました ()
- New PFNが、NICTとの共同研究の成果である事前学習モデルをベースとした国産生成AI基盤モデル「PLaMo 3.0 Prime」をリリースしました ()
- 災害時にSNSで拡散される偽情報の脅威に関する日経新聞の特集記事で、能登半島地震でSNSに投稿された救助要請の約1割がデマと推定されるというNICTによる分析が紹介されました ()
- 鳥澤フェローが参加した、デジタル庁が開催した「ガバメントAIフォーラム」でのパネルディスカッションの動画が公開されました ()
- 災害時のSNS上での偽情報拡散に関する毎日新聞の特集記事で、能登半島地震でSNSに投稿された救助要請の約1割がデマと推定されるというNICTによる分析が紹介されました ()
- PFNが、NICTとPFNが共同開発した事前学習モデルをベースとする国産の生成AI基盤モデルPLaMo 3.0 Prime β版 をリリース、モニター企業の募集を開始しました ()
- 東日本大震災から15年での特集記事などで、能登半島地震でSNSに投稿された救助要請の約1割が虚偽だったというNICTによる分析が紹介されました ()
- SB Intuitionsと高性能LLMの安全性技術に関する共同研究を開始しました ()
鳥澤フェローが、日本経済新聞社が主催する文学賞第14回 日経「星新一賞」の最終審査員に選出されました。日経「星新一賞」は、2013年に創設された、数多くのSF短編小説を生み出した小説家星新一氏の名前を冠した「理系的発想からはじまる文学賞」です。NICTは、日経「星新一賞」のビジョンから読み解ける “日本に必要なのは圧倒的想像力であり、その力が未来をつくる” という考え方に共感し、第14回 日経「星新一賞」に協力いたします。
電波タイムズによるNICTオープンハウス2026のレポート記事で、DIRECTから展示を行った、大規模Webデータとの照合結果を提示することでLLMの生成結果を検証するシステムWISDOM-CEが詳しく紹介されました。
NICTは、株式会社Preferred Networks(以下、PFN)と大規模言語モデルに関する共同研究を進めてきました。このたび、PFNは、本共同研究の成果である事前学習モデルをベースに、国産の生成AI基盤モデル「PLaMo」のフラッグシップモデル「PLaMo 3.0 Prime」を独自に開発し、β版の試験利用期間を経て提供を開始しました。様々なWEBニュースで取り上げられ、NICTとの共同研究やNICT提供データの活用に関しても紹介されています。詳しくは、PFNによるニュースリリースをご覧ください。
- Preferred Networksが国産生成AI基盤モデル「PLaMo 3.0 Prime」をリリース (NICTのお知らせ:2026年6月22日)
- 国産生成AI基盤モデルPLaMo 3.0 Primeを正式リリース (PFNのニュースリリース:2026年6月22日)
- PFN、国産生成AI基盤モデルPLaMo 3.0 Primeを正式リリース (電波タイムズ:2026年6月22日)
- PFN、国産フラグシップLLMの最新版を正式リリース--企業の実用性を向上 (ZDNET Japan:2026年6月22日)
- 国産生成AI基盤モデル「PLaMo 3.0 Prime」がβ版から正式版へ (AI Watch:2026年6月22日)
- PLaMo 3.0 Prime正式リリース|国産生成AIが「日本語で考える」段階へ (innovaTopia:2026年6月22日)
- PFN、国産生成AIモデル「PLaMo 3.0 Prime」を正式リリース (& SMART:2026年6月23日)
- プリファード、フルスクラッチ開発の国産生成AI基盤モデル「PLaMo 3.0 Prime」を正式提供 Reasoning/Non-reasoningモデルをAPI・オンプレで展開 (Ledge.ai:2026年6月25日)
- Preferred Networks、国産生成AI基盤モデル「PLaMo 3.0 Prime」を正式提供開始。 (AISmiley:2026年6月25日)
災害時にSNSで拡散される偽情報の脅威に関する日経新聞の特集記事で、24年の能登半島地震で発災後24時間にX(旧Twitter)に投稿された救助要請の約1割がデマと推定されるという、NICTによる災害状況要約システムD-SUMMを用いた分析が紹介されました。
- 熊本地震でライオン逃げた… 災害デマの脅威「見抜く自信なし」8割(日経新聞:2026年4月14日)
- 【社会】災害デマ拡散 脅威増す 熊本地震「ライオン逃げた」投稿 AIで精巧、対策後手に 「見抜ける自信ない」8割 民間調査(日経新聞:2026年4月14日朝刊39面)
3月上旬にデジタル庁が霞が関の職員を対象に開催した「ガバメントAIフォーラム:AIと創る、2030年の公共サービス」で実施された、AI時代の公共サービスの価値と未来像、そしてAI導入に伴う技術・組織の課題についてのパネルディスカッションのアーカイブ動画が公開されました。鳥澤フェローは、第二部のパネルディスカッション「ガバメントAIをどう作るか 〜開発戦略から官民連携まで〜」に参加し、デジタル庁のメンバーやPreferred Networksの岡野原社長など、官民のトップランナーと議論を行っています。
災害時のSNS上での偽情報拡散に関する毎日新聞の特集記事で、2024年1月の能登半島地震で地震発生後24時間以内にX(旧Twitter)に投稿された救助要請の約1割が住所が実在しないことなどからデマと推定されるという、NICTによる災害状況要約システムD-SUMMを用いた分析が紹介されました。
- 偽情報「2次災害」級 多数閲覧で収益、背景か(毎日新聞:2026年4月7日)
- [クローズアップ]偽情報「2次災害」級 多数閲覧で収益 背景か SNS有効活用 模索(毎日新聞:2026年4月7日朝刊3面)
株式会社Preferred Networks(以下、PFN)は、NICTとPFNが共同開発した事前学習モデルをベースとする国産の生成AI基盤モデルPLaMo 3.0 Prime β版 をリリースし、モニター企業の募集を開始しました。PLaMo 3.0 Prime β版では、PFNがこれまで蓄積してきた独自データセットに加え、新たに構築した医療分野に特化したデータセット、NICTが整備する日本語関連データセットも学習に活用され、日本語特有の文脈理解や論理展開への対応力が強化されています。詳しくは、PFNによるニュースリリースをご覧ください。
東日本大震災から15年での特集記事などで、2024年1月の能登半島地震で地震発生後24時間以内にX(旧Twitter)に投稿された救助要請の約1割が虚偽だったという、NICTによる災害状況要約システムD-SUMMを用いた分析が紹介されました。
- #確かな情報を得る訓練 防災行動の動機を高める「確かな情報」は何か。(日経サイエンス:2026年3月9日朝刊1面)
- [NEWS潮流深層]東日本大震災15年 防災 カギ握る新興企業 SNS情報 AIが検証 データグリッド(読売新聞:2026年3月11日朝刊11面)
この度NICTは、SB Intuitions株式会社(SBI)と、高性能大規模言語モデル(LLM:Large Language Model)の安全性技術に関する共同研究を開始しました。この共同研究では、NICTが長年にわたり蓄積してきた高品質な言語資源ならびに不適切出力の検出・抑制といったLLMの安全性確保のための技術と、SBIが国産LLM 「Sarashina(さらしな)」の開発等で培ってきた高度なモデル構築のノウハウを組み合わせることで、より高い安全性を備えた高性能なLLMの開発を目指します。詳細は、プレスリリース「SB Intuitionsと情報通信研究機構、高性能LLMの安全性技術に関する共同研究を開始」をご覧ください。
- SB Intuitionsと情報通信研究機構、高性能LLMの安全性技術に関する共同研究を開始 (NICTのプレスリリース:2026年2月26日)
- SB Intuitions and NICT Launch Joint Research on Safety Technology for High-Performance LLMs (NICT Press Release:February 26, 2026)
- SB Intuitionsと情報通信研究機構、高性能LLMの安全性技術に関する共同研究を開始 (SBIのプレスリリース:2026年2月26日)
- 倫理観などに沿った「信頼性高い国産AI」構築へ、NICTとソフトバンク子会社が技術開発で連携 (読売新聞オンライン:2026年2月26日)
- 【経済】安全なAI 官民で開発…情報通信機構・ソフトバンク (読売新聞朝刊10面:2026年2月26日)
- ソフトバンク子会社のAI企業、NICTと共同研究 “安全なAI”実現へ (ITmedia AI+:2026年2月26日)
毎日新聞の連載記事「AI新世紀」で、NICTによる大規模な日本語データの整備とそのデータに基づく日本語特化型の大規模言語モデルの開発が紹介されました。データの特徴や開発の意義について語った鳥澤フェローのインタビューや、、NICTとPFN、さくらインターネットとの連携についても取り上げられています。
- AI新世紀 オープンAIも狙った垂涎の日本語データ 「国産」の強みにできるか(毎日新聞WEB:2025年12月29日)
- AI新世紀 -覇権の行方-(3) 日本語データ狙う米(毎日新聞:2025年12月29日朝刊第1面)
- AI新世紀 -覇権の行方-(3) 国産 強み活かせるか 蓄積データ文庫本45億冊分(毎日新聞:2025年12月29日朝刊第2面)
NHK NEWS おはよう日本のおはBizで、生成AIの回答などのリスクを評価する新たな基盤システムの開発をNICTが目指していることが紹介されました。生成AIの出力テキストに対して指示情報や矛盾情報を裏取り結果として提示するWISDOM-CEの画面や、開発のねらいについて語った鳥澤フェローのインタビューなどが放送されました。
読売新聞による国産生成AI開発に関する提言の関連記事で、NICTとPFNの連携による国産生成AIの開発が取り上げられました。関連して同日の林総務大臣による閣議後記者会見でもNICTの活動が紹介されています ()
読売新聞が国産生成AI開発に関する「信頼できる生成AI」との共生に関する提言を発表、関連動向の紹介記事で、NICTとPFN、さくらインターネットが国産生成AIのエコシステム構築を目指して締結した基本合意の中で紹介したNICTとPFNの連携による国産生成AIの開発が取り上げられました。また、同日の林総務大臣による閣議後記者会見では、NICTによる高品質な日本語学習データの整備と民間などへの提供、能動的評価基盤構築の構想などが、総務省における関連の活動として林総務大臣より紹介されています。
日経主催による生成AIサミット(Generative AI Summit)2025GenAI/SUM(AI共創時代の未来図 〜経済、社会、教育)が10月6日〜8日に開催され、 鳥澤フェローが、パネルディスカッション「ソブリンAI時代の羅針盤 ~日本が目指すデータの自立と文化圏の創造」に登壇してNICTによる日本語学習データセットの整備や能動的評価基盤構築の構想に関して紹介、その内容が日経BizGateに掲載されました。
林総務大臣の閣議後記者会見でNICTで構想中の生成AIの信頼性・安全性を評価する能動的評価基盤が取り上げられ、NICTが保有するAI学習用の大量の日本語データの整備・拡充、AIの信頼性を評価する基盤技術の研究開発などについて紹介されました。この記者会見を受けて、AIの評価基盤開発に関する記事が、読売新聞や産経新聞など、様々なメディアに掲載されました。
- 林総務大臣閣議後記者会見の概要(総務省:2025年11月18日)
- 林総務相「日本の文化や歴史の理解備えたAI開発力が必要」…AIの信頼性「AIで評価」のシステム開発へ(読売新聞オンライン:2025年11月18日)
- AI信頼性 評価システム早期開発へ 総務相「来年度一部試行」(読売新聞:2025年11月19日朝刊第9面)
- 総務省、AIの信頼性評価に向けた基盤開発に着手 来年度にも提供へ(産経ニュース:2025年11月18日)
- AIリスク、国が評価基盤を開発へ 来年度試作を林総務相が表明(産経新聞:2025年11月19日朝刊10面)
- AI信頼性評価へ基盤開発 総務省、来年度提供へ(YAHOO!ニュース:2025年11月18日)
- 総務省、生成AIの信頼性評価基盤を構築へ 「信頼できるAI」の評価基盤、2026年度中に試作モデルを提供(ビジネス+IT:2025年11月18日)
- Japan plans to develop system of AI evaluating credibility of other AI models(ASIA NEWS NETWORK:2025年11月19日)
NICTで構想中の生成AIの信頼性・安全性を評価する能動的評価基盤が、読売新聞朝刊一面の記事「生成AIの信頼性、AIで評価し結果公表…総務省が基盤システム開発方針」や、日経新聞の記事「AIの安全性測るAI 総務省、来年度に試作」にて紹介されました。検索システムを含む多様なAIが連携し、AIを評価する様々な観点からの質問を自動的に生成して評価対象となるAIに回答を求め、その内容を検証するものです。
国産生成AIの必要性に関する読売新聞朝刊一面の特集記事「[AI近未来]第4部 覇権とルール<5>「国産」日本の命運左右」にて、生成AIの開発に関するPFNとNICTの連携が紹介されました。国産生成AIを開発している企業としてPFNが取り上げられ、NICTが20年近くかけて収集した膨大な日本語データの活用など、信頼性の高い国産生成AI開発をめざすPFNとNICTの連携に関して紹介されています。
クマに関するフェイク動画やデマ投稿が拡散されているという産経新聞の記事で、虚偽情報に対する心構えについて語った大竹センター長のコメントが紹介されました。
この度NICTは、農業・食品産業技術総合研究機構(農研機構)と、農業特化型生成AIモデルの構築に向けた連携を開始しました。NICTの強みである言語資源および情報処理技術を、農研機構が農業分野で培った知識と実証基盤と組み合わせて、信頼性の高い農業特化型生成AIモデルを共同で構築します。本取り組みで、農業特化型生成AIの精度と実用性の高度化が期待されます。詳細は、お知らせ「NICTは農研機構と連携し、農業特化型生成AIモデルの構築へ」をご覧ください。
NICTが開発した、LLMが生成したテキストに対して、根拠となりうる支持情報や、矛盾する情報・反論などをWebから探索して表示することで、ハルシネーションの可能性などを提示するシステムに関する記事が、日刊工業新聞に掲載されました。CEATEC2025にて、展示を行なったWISDOM-CE(Credible Evidence):LLM生成テキスト検証サービスに関して、大竹センター長が記者の取材に回答した内容が紹介されています。
国産生成AI開発の最新動向に関する記事で、NICTとPFN、さくらインターネットが国産生成AIのエコシステム構築を目指して基本合意を締結した件が紹介されました。毎日新聞の他、京都新聞、山陽新聞、佐賀新聞など、様々な地方紙に掲載されています。毎日新聞の記事では、鳥澤フェローが、共同通信によるインタビューで国産生成AI開発の必要性に関して語ったコメントも取り上げられています。
この度NICTは、株式会社Preferred Networks、さくらインターネット株式会社と、安心安全で日本社会と調和する国産生成AIのエコシステム構築を目指すことで基本合意を締結しました。この活動においてNICTは、これまでに独自に収集している700億ページを超える日本語Webページを活用するとともに、PFNと共同開発するLLMやNICTが独自に開発したLLM、さらにはこれまでに開発した動作原理の異なるAI等を組み合わせ、信頼性・創造性・多様性に富んだAI複合体を開発します。加えて、そのAI複合体を用いて、どの程度日本文化に沿った回答がなされるか、ハルシネーションが発生するか等を動的に評価し、弱点を改善するための学習データを自動生成できる能動的評価基盤を開発していきます。これにより、日本におけるより安心安全で日本社会と調和した生成AIの開発、普及、さらには日本全体の生産性向上に向けた活動を推進していきます。詳細は、プレスリリース「Preferred Networks、さくらインターネット、情報通信研究機構、安心安全で日本社会と調和する国産生成AIのエコシステム構築に向け、基本合意を締結」をご覧ください。
- Preferred Networks、さくらインターネット、情報通信研究機構、安心安全で日本社会と調和する国産生成AIのエコシステム構築に向け、基本合意を締結 (NICTのプレスリリース:2025年9月18日)
- Preferred Networks、さくらインターネット、情報通信研究機構、安心安全で日本社会と調和する国産生成AIのエコシステム構築に向け基本合意を締結 (PFNのニュースリリース:2025年9月18日)
- Preferred Networks、さくらインターネット、情報通信研究機構、安心安全で日本社会と調和する国産生成AIのエコシステム構築に向け、基本合意を締結 (さくらインターネットのニュースリリース:2025年9月18日)
- PFN、さくらインターネット、NICTが国産生成AIのエコシステム構築へ (ZDNet Japan:2025年9月18日)
- 「国内で完結する生成AI基盤」開発へ さくら、Preferred、NICTが協業 (ITmediaAI+:2025年9月18日)
- PFN、さくらインターネット、NICTが国産生成AIのエコシステム構築に向け基本合意を締結 (マイナビニュースTECH+:2025年9月18日)
- 国産AI開発、プリファードとさくらインターネットが協力 回答に信頼性 (日経新聞朝刊5面:2025年9月19日)
- 国産AI開発を政府が支援へ、学習データ提供し資金面も後押し…アメリカや中国依存を懸念 (読売新聞朝刊1面:2025年9月18日)
- 国産AI来春提供目標 基盤モデル 3者基本合意 (読売新聞朝刊11面:2025年9月19日)
- 「日本の文化や歴史理解した正しい日本語のAIを」 村上総務相が国産開発発表に期待表明 (産経ニュース:2025年9月19日)
日経新聞朝刊一面の記事「高品質データで国産AI 政府が計画案 国内外から開発人材」にて、NICTによる日本語特化型の独自大規模言語モデルの開発が取り上げられました。 KDDIとの共同研究についても紹介されています。
防災の日の9月1日、日刊工業新聞のコラム「産業春秋」にて、能登半島地震で地震発生後24時間以内にX(旧ツイッター)に投稿された案件の約1割が偽情報だったという、NICTによる災害状況要約システムD-SUMMを用いた分析が紹介されました。
テレビ朝日ANNストレートニュースでの【フェイクの波紋】特集にて、2024年の能登半島地震の際にSNSに投稿された救助要請の1割がニセ情報だったという、NICTによる災害状況要約システムD-SUMMを用いた分析が紹介されました。2016年の熊本地震の際と比べてニセ情報が大幅に増加した要因について語った鳥澤フェローのインタビューも放映されました。またABEMAnewsでも、取材を担当されたテレビ朝日社会部屋比久記者による解説で詳しく紹介されました。
大規模言語モデルNICT LLMの開発に向けたNICTによる良質な学習データ構築の取り組みに関する記事が、特集「超知能 迫る大転換」の第4回として、「良質データだけで育つ精鋭AI 『専属シェフ」』200人が選別」と題して、日経新聞の1面に掲載されました。アノテータによる学習データ作成作業の紹介とともに、日本文化に精通したAIの重要性を訴える鳥澤フェローのコメントも掲載されています。
- 2008年(平成20年)
- 知識創成コミュニケーション研究センター 言語基盤グループが発足(グループリーダー 鳥澤健太郎)。
音声・言語処理の基盤となる大規模な言語資源の構築・公開、及びその作成・活用に資する言語処理技術を研究。その成果として音声質問応答システム「一休」などのシステムを開発。 - 2011年(平成23年)
- ユニバーサルコミュニケーション研究所 情報分析研究室が発足(室長 鳥澤健太郎)。
Web等に存在する大量のテキストを深く意味的に分析し、情報の価値ある組み合わせや、価値ある仮説を柔軟な入力を元に提示できる技術の研究、開発。
- 2015年(平成27年)
- 大規模Web情報分析システムWISDOM Xの試験公開を開始(3月31日)。 対災害SNS情報分析システムDISAANAの試験公開を開始(4月8日)。
- 2016年(平成28年)
- ユニバーサルコミュニケーション研究所 データ駆動知能システム研究センターが発足(センター長 鳥澤健太郎)。
次世代音声対話システムWEKDAの研究開発を開始。 災害状況要約システムD-SUMMの試験公開を開始(10月18日)。 - 2018年(平成30年)
- SIP第2期「国家レジリエンス(防災・減災)の強化」において国立研究開発法人防災科学技術研究所、株式会社ウェザーニューズ、LINE株式会社と協力して、SNS上で災害関連情報の収集、配信等を自律的に行う防災チャットボットSOCDAの研究開発を開始。
- SIP第2期「ビッグデータ・AIを活用したサイバー空間技術」においてKDDI株式会社、NECソリューションイノベータ株式会社、株式会社日本総合研究所と協力し、次世代音声対話システムWEKDAの雑談応答技術も活用しつつ、高齢者の健康状態のチェックや社会的孤立の回避を狙ったマルチモーダル音声対話システムMICSUSの研究開発を開始。
- 2021年 (令和3年)
- WISDOM X 深層学習版の試験公開開始。自動並列化深層学習ミドルウェアRaNNCをリリース(3月31日)。
- 研究センター長に大竹清敬が就任(4月1日)。
- 2023年 (令和5年)
- 大規模言語モデルNICT LLMの研究開発を開始。
代表的な成果 1. 大規模言語モデルNICT LLM
NICT LLMは、WISDOM XやMICSUSなどの開発で培った高精度な言語処理・深層学習技術と、構築済みの350GBもしくは888GBの高品質な独自の日本語Webテキストを用いて開発した、NICT独自の生成系大規模言語モデルです。 これまでに、130億パラメータから1,790億パラメータ(OpenAI社のGPT-3と同等規模)、さらには日本語特化型では世界最大規模の大規模言語モデルとなる3,110億パラメータまで、パラメータ数を変えたさまざまなモデルの事前学習を完了し、特にファインチューニング等を行わなくても、事前学習のみで一定の精度で質問応答、創作、議論等が可能なことを確認し、また、モデルの大規模化と学習用テキストの大規模化に伴う性能向上を確認しています。
このNICT LLMの開発に関して2023年7月にプレスリリース「日本語に特化した大規模言語モデル(生成AI)を試作」を実施、多くの新聞やネットメディアで報道されています。 NHKニュース7でも当研究センターの活動が紹介されました。
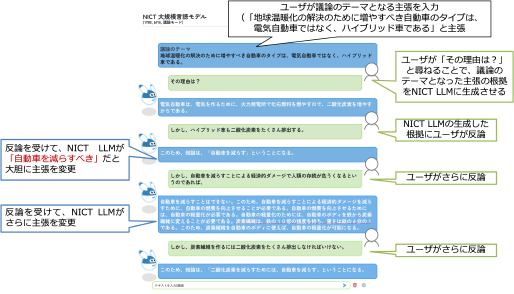
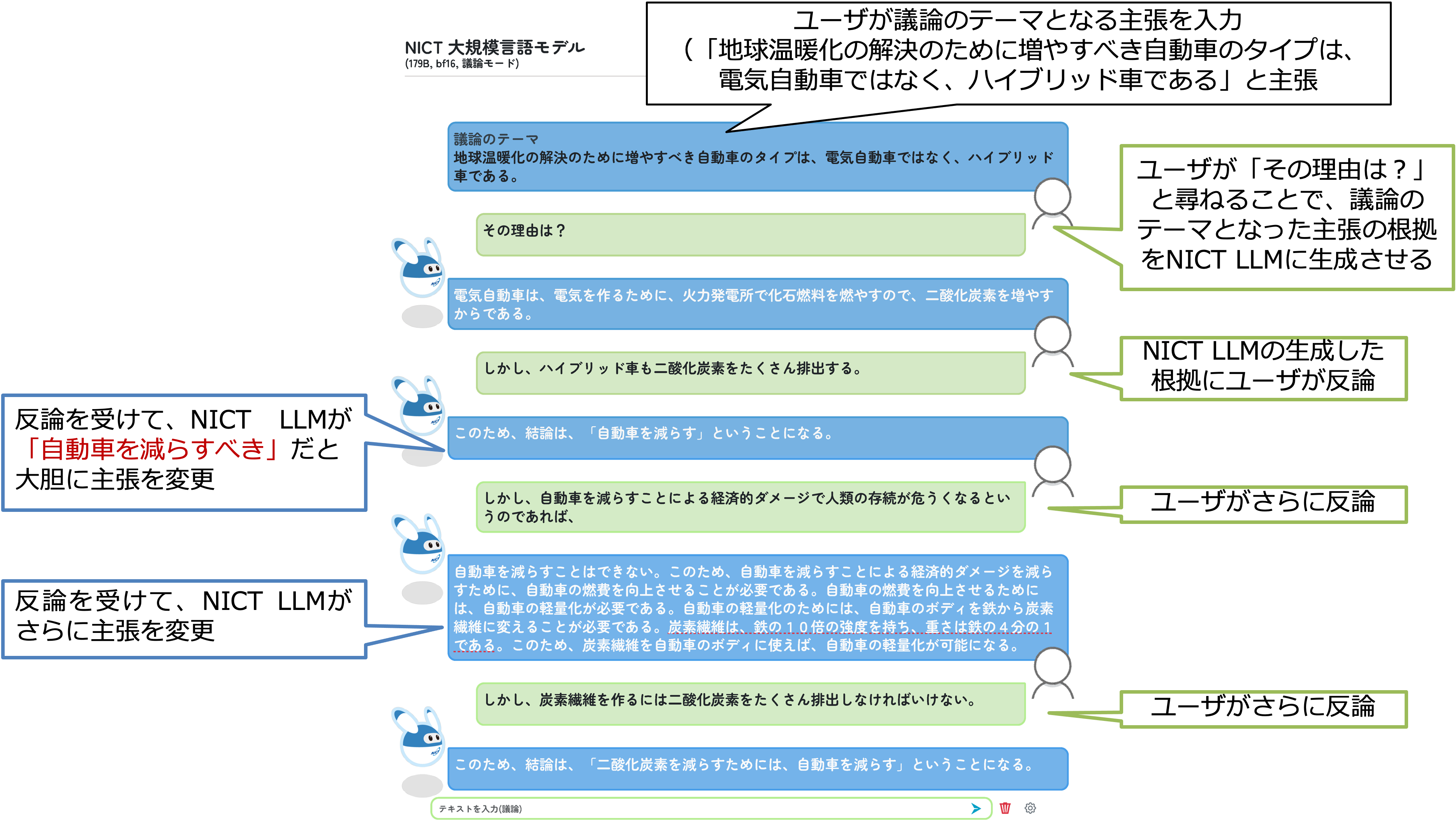
現在、偽情報を生成するハルシネーション等の生成系大規模言語モデルの副作用の抑制を目指して、WISDOM Xを活用した情報を確認する機構や、複数のLLM同志が議論を行って最終的な情報を生成するシステムの検討にも着手しています。また、NICT LLMおよび関連技術の社会実装に向け、MICSUSなどの対話システムへの導入を計画するとともに、NICTで収集・開発した言語資源や言語モデル、研究知見などを共同研究等を通して民間等に提供する準備も進めています。2024年7月1日にKDDIとの共同研究を開始しました。


- NICTとKDDIが大規模言語モデルに関する共同研究を開始 (NICTのプレスリリース:2024年7月1日)
- Building prototype Japanese language specific Large Language Models (LLM, Generative AI) NICT REPORT 2024
- 生成AIが互いに議論? 国立法人NICTが目指す「フェイクを見破る術」とは ITmediaビジネスオンライン 連載「生成AI 動き始めた企業たち」第8回:2023年9月6日
- 日本語に特化した大規模言語モデル(生成AI)を試作 NICTのプレスリリース:2023年7月4日
代表的な成果 2. 高齢者介護支援マルチモーダル音声対話システムMICSUS
MICSUSは、異次元の高齢化が進み介護人材の逼迫が喫緊の課題となる中、現在は人間の介護者(ケアマネジャー)が月一回程度面談で行なっている、 介護モニタリングと言われる高齢者の健康状態や生活習慣のチェックの一部を音声対話を通じて代替し、介護者の作業負担を軽減するための対話システムです。 また、Web情報を用いた雑談も行い、高齢者のコミュニケーション不足の抑制も狙っています。 内閣府戦略的イノベーション創造プログラム(SIP)第2期の支援により、KDDI株式会社、 NECソリューションイノベータ株式会社、株式会社日本総合研究所と共同で開発しました。
音声認識誤りに頑健な独自開発のHBERTを300万件のオリジナル学習データでファインチューニングしたモデルを活用し、遠まわしな言い回しなどを含む様々な発話に対して高精度な意味解釈を実現し、 高齢者との対話から健康状態や生活習慣の情報を適切に抽出します。 2022年度に全国各地の高齢者179名を対象に実証実験(総対話時間95.3時間、26,704ターン)を実施して評価を行いました。 実施後のアンケートで5段階中4.2と高評価をいただくとともに、言語処理の部分ではYES/NO疑問文への回答を93.5%の高精度で正しく意味解釈できています。 雑談的応答に関しても、91.8%が雑談として適切、25.4%に対して高齢者が笑顔を見せるなど、51.9%に対して高齢者が好意的反応を示し、雑談のクオリティは良好と言えます。
また、CEATEC2022、HANAZONO EXPO、けいはんなR&Dフェア2023など、 様々なイベントに出展して多くの家族づれや介護関係者にMICSUSとの対話を体験していただいています。
今後も、多数の民間企業と連携して本技術の社会実装に向けた強化を進めるとともに、さまざまな社会課題の解決、回避に向け、言語、音声の高度かつ高精度な意味的処理の実現を目指して研究開発を行います。 研究開発成果を、要素技術単位でKDDIをはじめとするさまざまな企業、組織にライセンス等を通して提供し、技術の社会実装に取り組んでいきます。 また、大規模言語モデルなどの最新の言語処理技術の応用も図っていきます。


高知県日高村での実証実験の様子(KDDI提供)
MICSUSの詳しい紹介は、以下のサイトや動画をご覧ください。
- 高齢者向け対話AIでケアマネジャー面談業務時間の7割削減に成功 NICTのお知らせ:2023年3月8日
- 介護人材不足解消に向け、対話AI搭載型ロボットによる介護実証を実施 KDDIのニュースリリース:2023年11月13日
- SIP第2期「ビッグデータ・AIを活用したサイバー空間基盤技術」研究成果報告書(2018年度~2022年度) 2023年 3月発行
- 高齢者介護支援用マルチモーダル音声対話システムMICSUS 情報通信研究機構研究報告 2022年12月発行
研究紹介ムービー『NICTステーション ~MICSUS~』(NA上白石萌音)
マルチモーダル音声対話システムMICSUS紹介動画
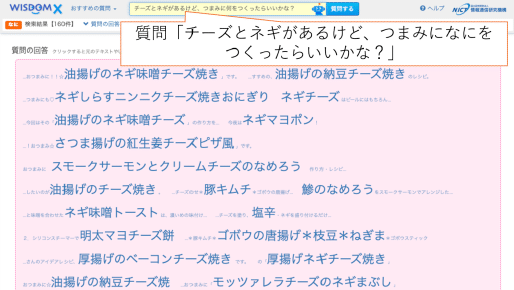
代表的な成果 3. 大規模Web情報分析システムWISDOM X 深層学習版
2021年3月31日より、Web60億ページの情報を基に様々な質問に回答することができる大規模Web情報分析システムWISDOM X(ウィズダムエックス)「深層学習版」の試験公開を開始しました。 2015年3月31日より試験公開しておりましたバージョンでは、Web40億ページの情報を基に「なに」「なぜ」「どうなる」といったタイプの様々な質問に回答することが出来ましたが、「深層学習版」では、新たに「どうやって」(How-to)型の質問にも対応しました。 これらの様々な質問応答を通して関連情報の全体像を迅速かつ容易に把握できるようにし、価値ある想定外の発見も容易にします。 WISDOM Xは、近年、重要性を増しているイノベーションやリスク管理といった不確実性に対処する作業において価値ある考えるヒントを提供できると考えています。
2023年6月12日にニアリアルタイム解析を導入し、収集したWebページを即時に解析し、WISDOM Xの分析対象とするようにしました。 これにより一部の最新の情報に対しても質問の回答が行えるようになっています。 (ただし、収集した時点で最新情報かどうかはわかりませんので、最新情報がすべて検索可能になっているわけではありません。)
2023年12月18日に深層学習モデルを更新しました(分析対象はWeb176億ページ以上)。「なぜ?」、「どうやって?」タイプの質問において実験では精度が5%以上向上しています。
深層学習版の詳細につきましては以下のリンクをご覧ください。